团团虾声明:本文翻译自 Medium 文章 Autoregressive next token prediction & KV Cache in transformers,作者 Frederik vom Lehn。原文发表于 2026 年 5 月。
理解 LLM 中加速 token 生成的优化技术。
大图景
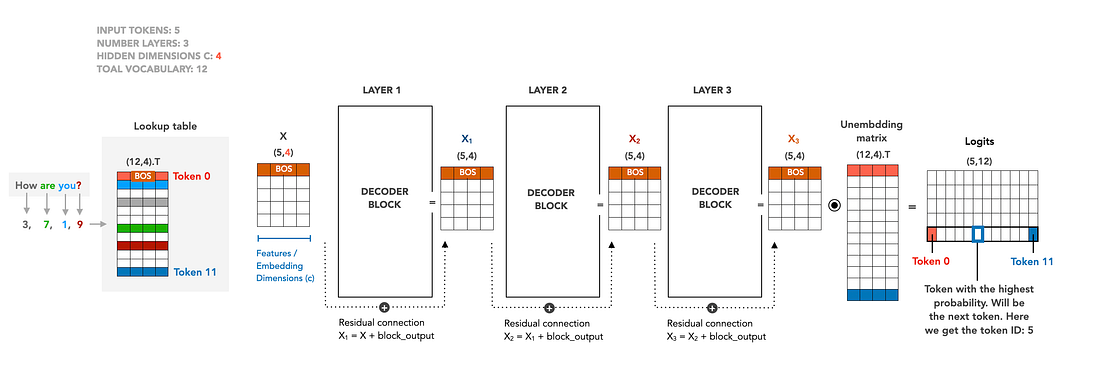
在深入注意力头、KV cache 和生成机制之前,先退一步,看看自回归语言模型到底长什么样。
一个 prompt 以纯文本形式进入:“How are you?”。分词器(tokenizer)将其切成词汇 ID——这里是 3、7、1、9,前面加了一个 BOS(“序列开始”)token。每个 ID 只是一个指向查找表的整数:查找表是一个形状为 (vocab_size, c) 的学习矩阵,每一行是词汇表中一个 token 的嵌入向量。为我们的 5 个输入 ID 选择对应的行,得到 X,一个 (5, 4) 矩阵——五个 token,每个位于一个 4 维的嵌入空间中。从这里开始,文本离开了符号的世界,进入了向量的世界。我们在例子中使用的是玩具维度。
从这里,X 流经一堆解码器块(decoder blocks)。每个块都是相同的架构——多头自注意力 + MLP——每个块将输入转换为相同形状的精炼 (5, 4) 表示。使深度 transformer 可训练的技巧是包裹在每个块周围的残差连接:不是替换输入,每个块在输入上叠加(X₁ = X + block_output)。信息沿着一条连续的”残差流”流动,每一层是对它的编辑而非覆盖。堆叠三个这样的块,得到 X₃,即最终的隐藏状态。
最后一步是对第一步的反向操作。解嵌入矩阵(unembedding matrix)——通常是查找表的转置,因为输入和输出词汇表相同——将 X₃ 的每一行投影回词汇空间,产生一个 (5, 12) 的 logits 矩阵:每个词汇 token 在每个位置上的得分。对于下一个 token 生成,只有最后一行有用。它的 argmax 就是模型接下来想说的 token。这里,那是 token ID 5。
以上就是整个前向传播的高空俯视图。本文的其余部分将放大到其中一个解码器块内部,以及那个使生成长序列成为可能的优化技术——KV cache。
让我们放大来看,在第一次前向传播中,一个解码层内部发生了什么。
Prefill 前向传播
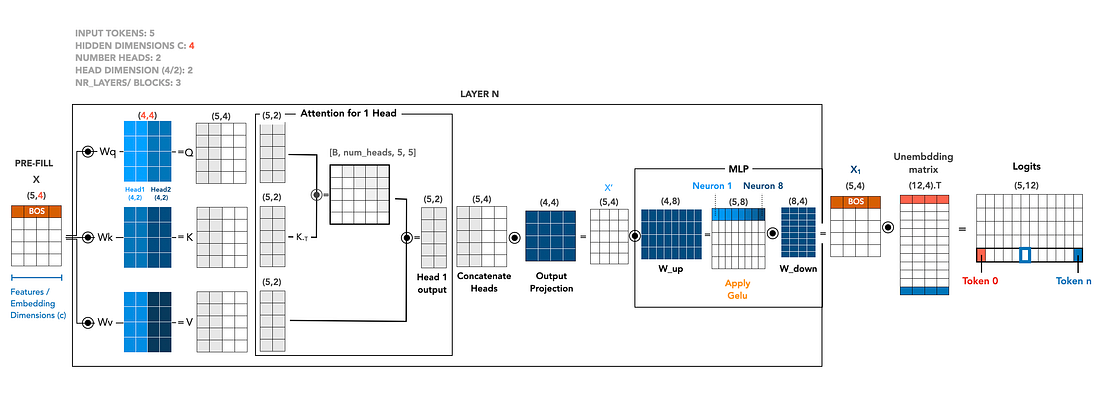
在语言模型生成第一个新 token 之前,它必须先处理 prompt。这一步(prefill)在单次并行前向传播中将整个输入序列跑过整个网络。它的任务有两方面:产生第一个预测的 token,以及填充 KV cache,使后续的 decode 步骤保持高效。
让我们在一个小模型中,梳理一个 5-token prompt 的处理过程:隐藏维度 c = 4,2 个注意力头,词汇表大小 12。
从 tokens 到 Q、K、V
输入 X 以 (5, 4) 矩阵的形式到达:5 个 token,每个由从查找表中提取的 4 维嵌入表示。三个学习到的投影矩阵 Wq、Wk、Wv,每个形状为 (4, 4),将 X 变换为 query、key 和 value 矩阵 Q、K、V,它们都是 (5, 4) 形状。
因为我们有 2 个头,每个 (5, 4) 矩阵按列方向拆分为两个 (5, 2) 切片,每个头一个。每个头将在自己的 2 维子空间中独立计算注意力。
一个头内部的注意力
在单个头内部,注意力是一种加权查找。该头的 Q 切片 (5, 2) 乘以其 K 切片的转置,得到一个 (5, 5) 的注意力分数矩阵——每个 token 的 query 与每个 token 的 key 做点积。经过缩放和 softmax(以及因果掩码,因为这是自回归模型,token t 不能看到 > t 的 token),该矩阵的每一行变成一个概率分布,表示”我应该从哪些过去的 token 中获取信息”。
这些权重然后乘以该头的 V 切片 (5, 2),得到该头的输出,形状为 (5, 2):每个 token 现在持有来自其允许位置的 value 向量的、上下文感知的混合。
拼接与投影
两个头的输出拼接回 (5, 4) 矩阵,然后通过一个输出投影 (4, 4)。结果 X’ 仍然是 (5, 4),与输入形状相同,但每一行现在反映了从整个序列收集到的信息。
MLP
每个 token 的向量然后独立地通过一个两层 MLP。W_up 形状为 (4, 8),将每一行扩展到 8 维,GeLU 添加非线性,W_down 形状为 (8, 4),投影回原始维度。输出 X₁ 是 (5, 4),在实际模型中,这将会送入下一个 transformer 块。堆叠几个这样的块(这里假设 3 层),就得到了完整的前向传播。我们假设这里是最后一层。
Logits 与第一个预测
在最后一层之后,(5, 4) 的隐藏状态乘以解嵌入矩阵 (12, 4)⁺(即 (12, 4) 的转置),产生形状为 (5, 12) 的 logits——每个词汇 token 在每个位置上的得分。对于生成,只有最后一行重要:它告诉我们模型认为 token 5 之后应该跟什么。对该行取 argmax(或采样),得到第一个生成的 token。在我们的例子中是 token ID 5。
Cache 保存了什么
这里有一个安静但关键的部分:在这一次前向传播中,每一层为 prompt 计算了形状为 (5, 4) 的 K 和 V。这些张量被存储下来。它们是未来 token 在这一层中需要知道的关于 prompt 的所有信息。嵌入、query、MLP 激活——全部丢弃。从这里开始,生成进入 decode 模式,一次处理一个新 token,并从 cache 中读取而不是重做工作。
现在让我们理解大图景——使用 KV cache 生成下一个 token 时发生了什么。
使用 KV Cache 的 Decode 步骤
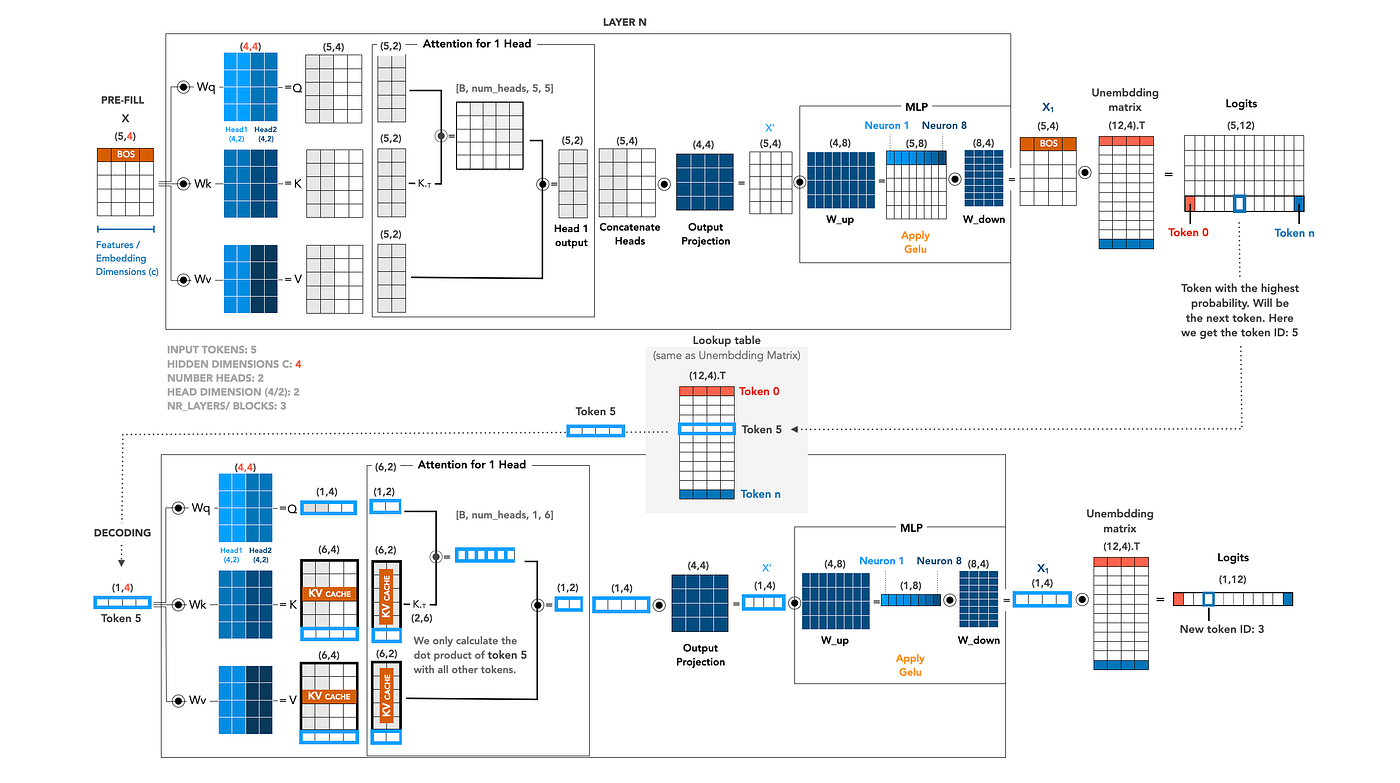
一旦 prefill 完成,模型切换到 decode 模式。后续的每个 token 通过一次前向传播生成,这次前向传播在结构上看起来和 prefill 相似——但每次只操作一行,依赖 KV cache 记住之前的一切。
让我们继续我们的例子。Prefill 预测了 token 5,所以我们现在将 token 5 作为输入送回去进行下一步。
一个 token 进,一个 token 出
新的输入 X 是一个单行,形状为 (1, 4),就是 token 5 的嵌入,从 prefill 时使用的同一个查找表中提取。之前的 5 个 prompt token 不会被重新送入。它们不需要:模型在这一层需要它们的所有信息已经躺在 cache 中了。
将这一行 (1, 4) 乘以 Wq、Wk、Wv(每个仍然是 (4, 4)),得到新的 Q、K 和 V,每个形状为 (1, 4)。只有新 token 会计算其 query、key 和 value。
追加到 cache
新计算出的 K 和 V 行被追加到上一步缓存的 K 和 V 矩阵中。Prefill 之后 cache 包含 (5, 4),现在它包含 (6, 4)——来自 prompt 的五行加上 token 5 的一行新数据。这个拼接后的张量就是注意力将要读取的内容。
针对 cache 的注意力
像之前一样拆分到各头,每个头现在有一个形状为 (1, 2) 的 query 和形状为 (6, 2) 的完整 key/value 矩阵。点积 Q · Kᵀ 产生一个 (1, 6) 的分数行——token 5 对所有 6 个位置的注意力权重,包括它自己。这里不需要因果掩码:每个缓存位置天然都在过去,因此每个分数都是有效的。
Softmax 将其变为一个概率分布,对 V (6, 2) 的加权求和产生一个 (1, 2) 的头输出。拼接两个头得到 (1, 4),输出投影 (4, 4) 产生形状为 (1, 4) 的 X’。
为什么这很重要
比较一下形状。Prefill 处理了 (5, 4) 的输入,在 5 行上并行执行所有操作——这是填充 cache 所必需的。Decode 处理 (1, 4) 的输入,在单行上执行所有操作,cache 在需要的地方(注意力内部)静静地提供历史上下文。MLP、投影、解嵌入——所有的工作量都是无 cache 前向传播的 1/N。
这就是长上下文生成之所以可行的全部原因。没有 KV cache,每个新 token 意味着重做整个 prefill,每次都稍微更长一点——生成 N 个 token 的成本会呈二次方增长。有了它,每个新 token 的计算量大致相同,加上一个针对不断增长的 cache 的廉价注意力求和。
生成一个 token,本质上是一小部分新鲜工作,站在大量已记住工作的肩膀上。
原文:Autoregressive next token prediction & KV Cache in transformers — Frederik vom Lehn, Advanced Deep Learning, May 2026